Табличное мастерство. Осваиваем модели машинного обучения для анализа табличных данных

000
ОтложитьЧитал

Введение в табличные данные и машинное обучение
В современном мире машинное обучение играет все большую и большую роль в повседневной жизни, бизнесе и научных исследованиях. Умение анализировать и использовать данные становится ключевым фактором успеха для организаций и профессионалов. Эта книга призвана стать вашим комплексным руководством по машинному обучению, особенно в отношении анализа табличных данных, которые являются наиболее распространенным типом данных в бизнесе.
Данная книга будет полезна как бизнесу, руководителям проектов по машинному обучению, так и лицам, интересующимся машинным обучением. Она предоставляет широкий обзор методов и подходов, используемых для анализа и прогнозирования на основе табличных данных, включая классические алгоритмы машинного обучения, ансамблирование, автоматическое машинное обучение (AutoML) и применение нейронных сетей.
Книга разделена на несколько глав, каждая из которых посвящена определенному аспекту машинного обучения. Вы узнаете о предобработке данных, отборе признаков, разработке и валидации моделей, а также о внедрении и мониторинге решений на основе машинного обучения в реальной среде. Кроме того, в книге рассматриваются важные вопросы этики и соответствия законодательным требованиям в контексте машинного обучения.
Благодаря практическим примерам и пошаговым инструкциям, вы сможете глубже погрузиться в каждый этап разработки проекта машинного обучения и получить полезные навыки для своей карьеры или бизнеса. Независимо от вашего опыта или роли, вы найдете ответы на свои вопросы, а также полезные советы и рекомендации по применению машинного обучения в различных областях.
Мы надеемся, что эта книга станет вашим надежным спутником на пути к успешному освоению и применению машинного обучения, и поможет вам создавать инновационные и эффективные решения для вашего бизнеса, проектов и личного развития.
Книга предназначена для людей с разным уровнем опыта в области машинного обучения: от новичков до опытных профессионалов. В каждой главе представлены материалы как для начинающих, так и для более продвинутых читателей, что позволяет каждому найти подходящий для себя уровень сложности и глубину изложения.
Основы табличных данных
Табличные данные – это распространенный вид структурированных данных, представленных в виде таблицы, состоящей из строк и столбцов. Строки обычно соответствуют отдельным объектам или наблюдениям, а столбцы представляют различные переменные или характеристики объектов. Табличные данные могут содержать числовые значения, категориальные значения, текст, даты и другие типы информации.
Машинное обучение и его виды
Машинное обучение (МО) – это подраздел искусственного интеллекта, который позволяет компьютерам учиться и принимать решения без явного программирования. МО использует алгоритмы и статистические модели для анализа и обработки данных с целью делать предсказания или принимать определенные решения.
Методы машинного обучения и нейронные сети являются частями области искусственного интеллекта, но они имеют свои особенности и различия.
Методы машинного обучения включают в себя широкий спектр алгоритмов, которые используются для обучения моделей на основе данных.
Выделяют три категории машинного обучения:
Обучение с учителем: модели обучаются на основе размеченных данных, где каждому объекту сопоставляется метка или значение. Примеры таких методов включают линейную регрессию, деревья решений и метод опорных векторов.
Обучение без учителя: модели обучаются на основе неразмеченных данных, и целью является выявление структуры или зависимостей в данных. Примеры таких методов включают кластеризацию и методы понижения размерности.
Обучение с подкреплением: модели обучаются на основе взаимодействия с окружающей средой, где они получают награды или штрафы за свои действия. Примеры таких методов включают Q-обучение и глубокое обучение с подкреплением.
Нейронные сети – являются подмножеством методов машинного обучения, которые имитируют структуру и функционирование биологических нейронных сетей. Они состоят из слоев нейронов, связанных синапсами, и обучаются путем оптимизации весов синапсов.
Синапсис в контексте искусственных нейронных сетей – это аналог биологического синапса, который служит связью между искусственными нейронами. В искусственных нейронных сетях синапсисы представлены в виде весов, которые обозначают силу связи между нейронами.
Когда сигнал передается от одного нейрона к другому через синапсис, он умножается на вес связи (величина синаптического веса). Веса могут быть положительными или отрицательными, что соответственно усиливает или ослабляет передаваемый сигнал. В процессе обучения нейронной сети веса синапсов оптимизируются для минимизации ошибки и улучшения производительности модели.
Синапсисы играют ключевую роль в передаче информации между нейронами и определении архитектуры и динамики нейронных сетей. Они позволяют нейронным сетям адаптироваться и обучаться на основе предоставленных данных, делая их мощным инструментом для решения сложных задач машинного обучения.
Нейронные сети могут быть использованы для решения задач обучения с учителем, обучения без учителя и обучения с подкреплением.
Основные отличия между методами машинного обучения и нейронными сетями:
Структура: Нейронные сети имеют иерархическую структуру слоев и нейронов, в то время как многие методы машинного обучения используют другие структуры, такие как деревья, графы или линейные модели.
Сложность: Нейронные сети обычно обладают большей сложностью и гибкостью, что позволяет им аппроксимировать более сложные функции и зависимости в данных. Однако, это также может привести к более длительному времени обучения и требовать больших вычислительных ресурсов.
Обработка данных: Нейронные сети обычно более способны справляться с большим количеством данных и могут автоматически извлекать признаки из сырых данных, что может быть полезным для таких задач, как обработка изображений, текста и звука. В то время как традиционные методы машинного обучения часто требуют предварительной обработки данных и ручного извлечения признаков.
Устойчивость к переобучению: В силу своей сложности, нейронные сети более подвержены переобучению, когда модель слишком хорошо обучается на тренировочных данных, но плохо справляется с новыми данными. В отличие от этого, многие традиционные методы машинного обучения, такие как линейная регрессия или решающие деревья, могут быть менее подвержены переобучению, особенно при использовании регуляризации или прунинга.
Регуляризация и прунинг – это две техники, используемые в машинном обучении для борьбы с переобучением и улучшения обобщающей способности моделей.
Регуляризация: Регуляризация – это метод добавления штрафа к функции потерь модели с целью предотвратить переобучение и упростить модель. Регуляризация в основном ограничивает значения параметров модели, делая ее менее сложной и более устойчивой к шуму в данных. Два наиболее распространенных типа регуляризации – L1 (Lasso) и L2 (Ridge) регуляризации.
L1-регуляризация добавляет абсолютные значения весов модели к функции потерь, что приводит к тому, что некоторые веса становятся равными нулю, что эквивалентно удалению соответствующих признаков из модели. L2-регуляризация добавляет квадраты весов к функции потерь, что снижает значения весов, но не делает их строго равными нулю.
Прунинг (обрезка): Прунинг – это процесс удаления некоторых частей модели (например, узлов или ветвей дерева решений, нейронов в нейронных сетях) с целью уменьшения сложности модели и предотвращения переобучения. Применяется главным образом в деревьях решений и ансамблях деревьев, таких как случайный лес или градиентный бустинг.
В деревьях решений прунинг может быть осуществлен путем удаления узлов или поддеревьев, которые вносят малый вклад в точность модели или создают слишком сложные структуры. Может быть применен как во время построения дерева (преждевременный прунинг), так и после его построения (отсроченный прунинг). Применение прунинга помогает снизить вероятность переобучения, улучшая обобщающую способность дерева.
Итак, и регуляризация, и прунинг являются техниками для упрощения моделей машинного обучения и предотвращения переобучения, но они применяются к разным типам моделей и используют разные подходы.
Интерпретируемость: Многие традиционные методы машинного обучения, такие как линейные модели или деревья решений, являются интерпретируемыми, что означает, что их результаты и принципы работы легче объяснить и понять. Нейронные сети, особенно глубокие сети, часто считаются "черными ящиками" из-за их сложной структуры и большого количества параметров, что затрудняет интерпретацию их предсказаний.
В целом, выбор между методами машинного обучения и нейронными сетями зависит от специфики задачи, доступных данных, вычислительных ресурсов и требований к интерпретируемости модели. В некоторых случаях использование нейронных сетей может привести к значительному улучшению результатов, в то время как в других случаях традиционные методы машинного обучения могут быть более подходящими и эффективными.
Статистический анализ данных и методы машинного обучения
Методы машинного обучения и статистический анализ являются инструментами для изучения и анализа данных, и выбор между ними зависит от конкретной задачи, целей и доступных данных. Вот несколько примеров, когда стоит использовать машинное обучение или статистический анализ:
Использование статистического анализа:
Описательная статистика: Если вам нужно просто описать основные характеристики данных, такие как среднее, медиана, стандартное отклонение и т. д., статистический анализ может быть достаточным.
Исследование взаимосвязей: Если цель состоит в изучении взаимосвязи между переменными и выявлении статистически значимых связей, такие методы, как корреляционный анализ или регрессионный анализ, могут быть подходящими.
Тестирование гипотез: В случае, когда вам нужно проверить определенную гипотезу о данных, такую как сравнение средних значений двух групп, статистические тесты могут быть использованы для этой цели.
Использование машинного обучения
Прогнозирование: Если задачей является прогнозирование значений одной переменной на основе других переменных, машинное обучение может обеспечить более точные и надежные прогнозы по сравнению со статистическими методами.
Классификация и кластеризация: Если вам нужно разделить данные на группы на основе их характеристик или выявить скрытые закономерности в данных, методы машинного обучения, такие как деревья решений, случайный лес, k-средних и другие, могут быть подходящими.
Работа с большими данными: Если у вас есть большие объемы данных или данные с большим количеством признаков, машинное обучение может быть более подходящим инструментом для анализа данных, поскольку оно способно обрабатывать такие данные и выявлять сложные закономерности.
Важно отметить, что статистический анализ и машинное обучение не взаимоисключающие подходы. На практике они часто используются совместно для анализа данных, и один подход может дополнять другой. Например, статистический анализ может быть использован на начальном этапе проекта для получения базового понимания данных и выявления потенциальных связей между переменными. Затем машинное обучение может быть применено для создания более сложных моделей и прогнозов.
В некоторых случаях, когда данные содержат линейные зависимости, и задача не требует высокой точности прогнозирования, можно использовать статистические методы, такие как линейная регрессия. Однако, если данные имеют сложные нелинейные зависимости или если требуется высокая точность прогнозов, машинное обучение может быть более подходящим инструментом.
В целом, выбор между статистическим анализом и машинным обучением зависит от специфики задачи, доступных данных и целей исследования. Важно помнить, что эти подходы могут дополнять друг друга и быть использованы совместно для достижения лучших результатов.
Задачи, решаемые с помощью анализа табличных данных
Анализ табличных данных с использованием машинного обучения позволяет решать различные задачи, такие как:
Регрессия – предсказание непрерывной переменной на основе входных данных.
Примеры: прогнозирование цен на жилье, автомобилей или акций и т.п.
Вот пример табличных данных, используемых для регрессии цен на автомобили:

В этом примере каждая строка представляет автомобиль, а столбцы содержат информацию о его марке, модели, годе выпуска, пробеге, типе топлива, литраже двигателя, мощности двигателя и цене.
Цель – предсказать цену автомобиля на основе его характеристик, например, для оценки стоимости при продаже или покупке. Эти данные могут быть использованы для создания модели машинного обучения, которая автоматически предсказывает цену автомобиля на основе его характеристик.
Классификация – определение категории или класса объекта на основе входных данных.
Примеры: определение кредитного риска, диагностика заболеваний или фильтрация спама.
Вот пример табличных данных, используемых для классификации диагнозов пациентов:
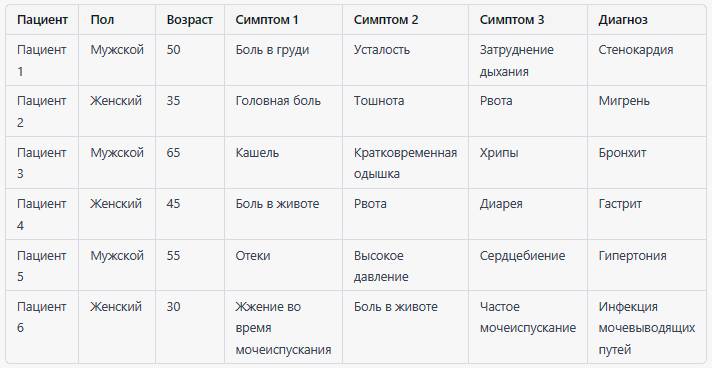
В этом примере каждая строка представляет пациента, а столбцы содержат информацию о его поле, возрасте, симптомах и диагнозе.
Цель – определить диагноз пациента на основе симптомов, например, для правильного назначения лечения. Эти данные могут быть использованы для создания модели машинного обучения, которая автоматически классифицирует диагноз пациента на основе его симптомов.
Кластеризация – группировка объектов на основе их схожести или близости друг к другу.
Примеры: сегментация клиентов, выявление аномалий в данных и т.п.
Вот пример табличных данных, используемых для кластеризации клиентов:

В этом примере каждая строка представляет клиента, а столбцы содержат информацию о его поле, возрасте, доходе и количестве покупок.
Цель – разбить клиентов на группы на основе их схожести, например, для улучшения маркетинговых кампаний или персонализированного обслуживания. Эти данные могут быть использованы для создания модели машинного обучения, которая автоматически разбивает клиентов на группы (кластеры) на основе их характеристик.
Ранжирование – упорядочивание объектов по определенному критерию или степени предпочтения.
Примеры: рекомендательные системы, поисковые движки или оценка релевантности рекламы.
Вот пример табличных данных, используемых для ранжирования результатов поиска:

В этом примере каждая строка представляет собой результат поиска, а столбцы содержат информацию о названии, описании и рейтинге соответствующего результата.
Цель – упорядочить результаты поиска по убыванию рейтинга, чтобы пользователю было легче найти наиболее релевантные результаты. Эти данные могут быть использованы для создания модели машинного обучения, которая автоматически ранжирует результаты поиска на основе описания и рейтинга.
Оптимизация – нахождение наилучшего решения для задачи с учетом ограничений и целевой функции.
Примеры: планирование маршрутов для логистики, распределение ресурсов или управление портфелем инвестиций.
Вот пример табличных данных, используемых для оптимизации распределения ресурсов:
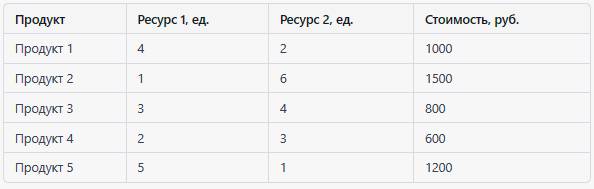
В этом примере каждая строка представляет продукт, а столбцы содержат информацию о необходимом количестве ресурсов 1 и 2 для его производства, а также о стоимости.
Цель – минимизировать общую стоимость производства продуктов, учитывая ограничения на количество доступных ресурсов. Эти данные могут быть использованы для создания математической модели, которая оптимизирует распределение ресурсов и находит наилучшее решение для данной задачи.
Прогнозирование временных рядов – анализ и предсказание значений переменных, измеряемых во времени.
Временные ряды являются подтипом анализа табличных данных, который фокусируется на изучении данных, собранных в различные моменты времени и представленных в хронологическом порядке. Временные ряды обычно используются для анализа изменений и тенденций в данных, прогнозирования будущих значений, выявления сезонности и аномалий.
Основная особенность временных рядов заключается в том, что данные имеют временную зависимость. Это означает, что значение признака в определенный момент времени может зависеть от его значений в предыдущие моменты времени. При анализе временных рядов используются специализированные методы и модели, которые учитывают эту временную зависимость.
Анализ временных рядов применяется в самых разных областях, таких как финансы (прогнозирование цен акций и обменных курсов), экономика (прогнозирование ВВП, инфляции), метеорология (прогнозирование погоды), здравоохранение (предсказание эпидемий) и многих других.
Вот пример табличных данных, используемых для анализа временных рядов в экономике:
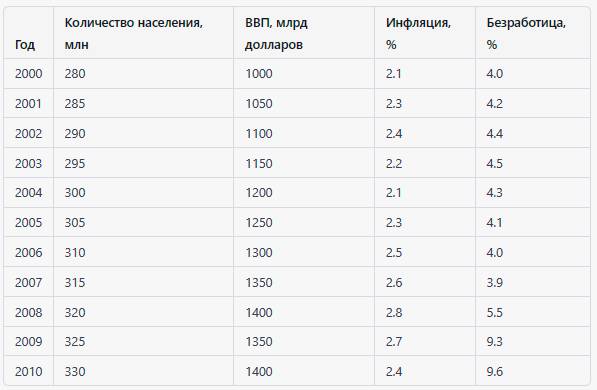
В этом примере каждая строка представляет год, а столбцы содержат информацию о количестве населения, ВВП, инфляции и безработице в соответствующем году. Эти данные могут быть использованы для анализа тенденций и прогнозирования будущих значений этих показателей. Например, на основе этих данных можно построить модель машинного обучения для прогнозирования ВВП на следующий год на основе количества населения и предыдущих значений ВВП, инфляции и безработицы.
Обработка естественного языка (NLP) – анализ и понимание текстовых данных в табличной форме. Примеры: анализ тональности текста, извлечение ключевых слов или автоматическая категоризация текстов.
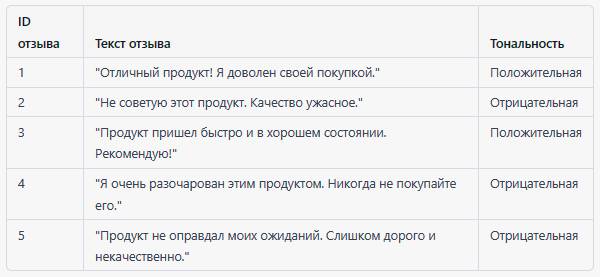
В этом примере каждая строка представляет собой отзыв на продукт, содержащий его текст и тональность (положительную или отрицательную). Эти данные могут использоваться для анализа качества продукта и выявления проблем, которые нужно решить. Они также могут использоваться для создания модели машинного обучения, которая может автоматически классифицировать тональность отзывов на продукт.
Анализ табличных данных с помощью машинного обучения может быть применен в широком спектре отраслей и сфер, таких как финансы, здравоохранение, розничная торговля, логистика, маркетинг, образование и многих других.
