




Введение
Здравствуй, читатель!
Эта книга написана для того, чтобы помочь начинающему или уже «продолжающему» системному администратору стать администратором вычислительного кластера или суперкомпьютера. Именно помочь, так как научить этому никакой книжке не под силу. Тем, у кого уже есть опыт администрирования Linux, учиться придётся меньше, но всё равно придётся обязательно. Тем, кто такого опыта не имеет, советуем почитать книги по администрированию Linux и потренироваться, например, на виртуальной машине. В этой книге мы коснёмся основ Linux, но лишь поверхностно.
Рассматривать будем только кластеры на базе Linux – это стандарт de-facto на настоящее время. Кластеры строят и на базе других ОС, например Windows, AIX и других, но здесь о них говорить не будем. Под суперкомпьютером мы понимаем вычислительный кластер, хотя большинство информации в этой книге применимо не только к кластерам. В тексте нами часто будет использоваться более широкое понятие – вычислительный комплекс. Все суперкомпьютеры разные, а уж кластеры и подавно – каждый со своими особенностями, требованиями и капризами. А значит, и навыки для каждого нужны свои.
Здесь мы собрали всё то, что, на наш взгляд, должно помочь в обучении системного администратора суперкомпьютера. Конечно, только прочитав книгу, нельзя сразу же стать настоящим администратором суперкомпьютера, но знания, заложенные в ней, помогут стать им намного быстрее.
Нами даже не ставилась цель охватить весь спектр технологий, программ, архитектур, которые применяются в суперкомпьютерах. Это не только невозможно, но и бесполезно: они изменяются, устаревают, сменяются новыми с такой скоростью, что книга безнадёжно устарела бы уже через несколько лет. В мире суперкомпьютеров ещё больше, чем в мире IT в целом действуют законы Льюиса Кэрролла: нужно бежать со всех ног, чтобы только оставаться на месте, а чтобы куда-то попасть, надо бежать как минимум вдвое быстрее.
Наша задача – рассмотреть самые распространённые на момент написания книги технологии, чтобы дать понятие об основных принципах, приёмах работы с ними. Это позволит с небольшими затратами начать их использовать, изучить более глубоко, освоить более новые версии, а также совсем новые технологии, архитектуры, программы. Чтобы всё-таки дать хотя бы небольшую практическую базу, мы будем приводить самые важные примеры прямо в тексте, а в последних трёх главах сжато изложены инструкции, приёмы и справочные данные рассмотренным по технологиям.
Главное, что авторам хотелось бы показать в книге, это то, что суперкомпьютер – не просто набор серверов, коммутаторов, дисков… Это единый комплекс – не только идеологически, но и по сути. Все компоненты его тесно связаны, и самая важная задача администратора – понять, осознать эти связи, значение каждой и её влияние на комплекс в целом. Конечно же, этого нельзя сделать, не умея контролировать все части комплекса, поэтому надо изучить особенности (хотя бы основные) настройки и мониторинга всех компонент конкретного кластера. Однако не следует думать, что, запомнив значение всех «галочек» в административных интерфейсах всех «железок», можно получить полный контроль над суперкомпьютером. Поскольку масштаб даже небольшого вычислительного кластера значительно отличается от десятка серверов, настоятельно (очень настоятельно) рекомендуем отнестись к изучению возможностей командной строки. Если работать с десятком серверов в графическом режиме ещё можно, хотя и очень утомительно, то с сотней – уже просто нереально.
Как выяснить, на каких серверах определился не весь объём оперативной памяти при последнем включении? Запустить на каждом «системный монитор»? Зайти на вкладку «система» и посмотреть объём ОЗУ? На это уйдёт весь рабочий день. А вот выполнив на каждом узле, например с помощью pdsh, команду типа
grep MemTotal /proc/meminfo | awk '{print $2}'
можно получить этот самый объём ОЗУ за секунды. Добавив ещё пару команд shell, можно сравнить полученное значение с эталоном (даже с учётом допусков) и выдать имена узлов, не прошедших проверку. Магия, вызываемая заклинанием? В чём-то – да, магия, но с понятными законами и вполне осваиваемая.
Нередко очень непростые действия можно выполнить с помощью комбинации стандартных команд. К счастью, это практически всегда возможно без большого труда. Труд потребуется для начального освоения этих команд, а потом – вся магия Linux будет в ваших руках! Очень советуем изучить «Advanced Bash Scripting Guide» (в Интернете есть хороший русский перевод). Это пособие позволит использовать огромную мощь инструмента, который всегда под рукой, – оболочки bash (практически всё работает и для zsh). Добавив в свой арсенал несколько простых приёмов sed и awk (а если захочется абсолютной магии, то и perl, а может быть, python или ruby), узнав возможности find, ps и подобных команд, вы многократно повысите эффективность своей работы.
В этой книге приведены также базовые знания о работе с командной строкой и основные понятия Linux, для того чтобы дать хороший старт тем, кто совсем с ними не знаком или знаком поверхностно. Без этих знаний и навыков невозможно понять работу системы в целом. Опытные администраторы Linux могут просмотреть эти главы бегло: для них там будет мало нового. А новичку они обязательны: нельзя быть администратором суперкомпьютера, не будучи хорошим Linux-администратором.
В книге затронута ещё одна важная тема, на первый взгляд не относящаяся к системному администрированию, – тема поддержки пользователей. Как известно, поддержка пользователей суперкомпьютера во многом отличается от поддержки пользователей компьютеров, которые работают в соседних комнатах. Мы постарались подготовить начинающего администратора к тем сложностям, которые ожидают его на этом пути. В каждой главе даны основные знания и понятия по той или иной теме. В некоторых из них раскрываются разные стороны одного и того же понятия. В конце каждой главы дано краткое резюме материала и ключевые слова для поиска в Интернете по теме главы.
Соглашения и обозначения, принятые в книге
Код скриптов, текст конфигурационных файлов выделяются так:
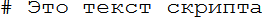
Предупреждения, важные моменты, о которых необходимо помнить:
Внимание! Не наступайте на одни грабли дважды!
Термины или важные понятия даны полужирным шрифтом.
Короткие команды выделяются в тексте так: ls -la.
Материал для новичков, который можно пропустить опытным специалистам, выделяется так:
Для начала работы включите компьютер в сеть.
В книге часто используются сокращения и распространённые термины. Для многих они привычны, для кого-то – пока нет. В отдельном словарике в конце пособия бóльшая их часть дана с расшифровками. Многие термины широко применяются как на русском, так и на английском языках. В основном нами используются русские варианты, а для того, чтобы не запутать читателя, в конце книги приведён список соответствий терминов, где также даны и русские «кальки», так как, к сожалению, многие начинающие используют только их и не знают корректного перевода.
Свои отзывы и пожелания, пожалуйста, присылайте на адрес superbook@parallel.ru.
Авторы выражают искреннюю благодарность:
Владимиру Воеводину за идеи и критику,
Александру Наумову и Антону Коржу за предоставленный материал и консультации,
Виктору Дацюку, Павлу Костенецкому, Алексею Лацису и Юрию Хребтову за важные замечания.
Вадиму Кузнецову (dikbsd) за неоценимую помощь в конвертации книги в электронный формат.
Глава 1. Что же такое «супер»?
Общие понятия о параллельной обработке и параллельных программах
Все современные суперкомпьютеры используют параллельную обработку данных. С самого начала компьютерной эры именно этот путь был и остаётся наиболее важным для достижения высокой производительности. Сейчас даже самый простой настольный компьютер если не многоядерный, то уж почти наверняка с технологией simultaneous multithreading (например, HyperThreading от Intel или AMD SMT), позволяющей работать двум (иногда более) программным потокам одновременно. Даже мобильные телефоны и фотоаппараты становятся параллельными и многоядерными.
Принцип параллельной обработки данных прост: если две или более операции независимы (т. е. результаты их выполнения не влияют на входные данные друг друга), то эти операции можно выполнить одновременно, т. е. параллельно. В аппаратуре традиционно есть два варианта воплощения этого принципа – параллелизм и конвейеризация.
Параллелизм – параллельное выполнение машинных команд разными устройствами. Например, команды x=a+b и y=b*c, где a, b и с – регистры, процессор может выполнить независимо, если он имеет раздельные устройства сложения и умножения (см. рис. 1). Этот принцип воплощён в большинстве современных процессоров.
Конвейеризация – разделение команд на этапы, каждый из которых выполняется быстро отдельным элементом аппаратуры, и выполнение этих этапов происходит по принципу конвейера: друг за другом. Таким образом, одновременно может выполняться несколько команд на разных стадиях конвейера. Наиболее часто этот принцип используется в векторизации – выполнении однотипной операции над векторами, т. е. массивами данных, расположенными в памяти регулярно (см. рис. 2).
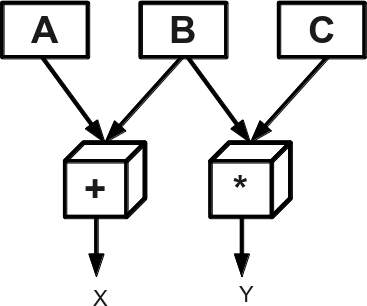
Рис. 1: Параллельное выполнение
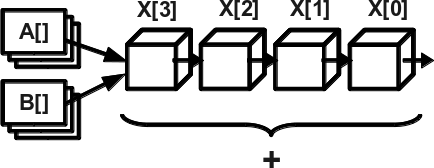
Рис. 2: Векторизация + конвейер
Чаще всего элементы вектора расположены друг за другом. Типичный пример – сложение векторов. Так как операция, выполняющаяся над векторами, одна и та же, то её разбивают на фазы – ступени конвейера. Например, загрузка элементов из памяти, нормализация мантисс, сложение, коррекция, запись в память. После выполнения первой ступени над первым элементом вектора эту стадию можно сразу же выполнить над вторым элементом, не дожидаясь завершения всей операции над первым. После завершения каждой ступени над одним элементом можно выполнить её над следующим. Таким образом, если самая медленная ступень конвейера выполняется за К тактов, а все ступени – за S тактов, то вектор из N элементов обработается за K*(N–1)+S.
Первый элемент обработается за положенные S тактов (это называется «время разгона конвейера»), а потом устройство будет выдавать по одному результату в K тактов. В современных процессорах чаще всего K=1. Однако конвейеризация не обязательно подразумевает векторизацию и наоборот. Например, если устройство сложения конвейерное и мы выполняем несколько обычных сложений подряд, они могут отлично задействовать конвейер.
Для системного администратора не всегда нужно доскональное понимание работы процессора, языка ассемблера и умение оптимизировать пользовательские программы, но понимание того, как устроено параллельное выполнение в процессоре, очень важно. Многие современные процессоры многоядерные, т.е. содержат несколько полноценных (или почти полноценных) процессоров на одном кристалле (в одной микросхеме). Естественно, что они могут работать параллельно. Есть ещё параллелизм на уровне доступа к памяти, когда разные банки памяти могут работать независимо, а значит, отдавать или записывать данные быстрее. Есть также параллелизм на уровне работы с устройствами – можно заранее сформировать в памяти блок для записи на диск или для отправки по сети и «скомандовать» контроллеру выполнить запись/передачу. Далее процессор может выполнять другие действия, а данные из памяти в это время будут записываться на диск или пересылаться по сети.
Это параллелизм, заложенный в «железе». Для того, чтобы задействовать его максимально, заставить вычислители (ядра, процессоры, вычислительные узлы…) работать параллельно, необходимо составить программу таким образом, чтобы она использовала все эти ресурсы. Т. е. написать параллельную программу. Этим мы заниматься не будем (по крайней мере, в рамках этой книги), но иметь дело с параллельными программами нам придётся постоянно, и знать, как они работают, нам необходимо.[1]
Если я написал параллельную программу, значит ли это, что она тут же заработает быстрее обычной (последовательной)? Нет. Более того, она может работать даже медленнее. Ведь части, которые должны исполняться параллельно, в реальности могут конфликтовать друг с другом. Например, две нити обращаются к разным участкам памяти и не дают эффективно работать кэшу процессора. Или параллельные процессы постоянно вынуждены ждать данных от самого медленного из них. Или…
Вариантов неэффективного параллельного кода много, и если не удаётся достичь хорошего ускорения программы на суперкомпьютере, то, возможно, она неэффективно использует параллелизм. Выяснить реальную причину очень трудно, для этого необходимо использовать «отладчики производительности» – параллельные профилировщики, трассировщики или хотя бы мониторинг вычислительных узлов, по данным которого можно судить о том, что происходит во время работы программы.
Для нас в первую очередь интересен параллелизм на уровне процессов UNIX (в том числе на разных узлах) и нитей. Именно здесь заложен основной потенциал параллельных приложений. Именно такой параллелизм используют наиболее популярные среды параллельного программирования MPI и OpenMP. Это не значит, что на других уровнях этого потенциала нет, но именно отсюда всегда нужно начинать. Среды (технологии) параллельного программирования представляют собой библиотеки или языки программирования, позволяющие упростить написание параллельных программ.
Для администратора важно знать, как устроена каждая среда, как она реализована технически, так как при возникновении проблем с программами потребуется понять, в чём причина неполадки. Даже если причина – ошибка в программе, нужно уметь показать это пользователю и подсказать ему путь решения проблемы. Параллельные программы, как правило, пишутся в терминах нитей или параллельных процессов (или всего вместе). То есть один и тот же код программы выполняется в разных нитях одного процесса (на разных процессорных ядрах) или в разных процессах, которые могут работать и на разных узлах.
Такой подход позволяет максимально задействовать все процессорные ядра – на каждом выполняется свой процесс или поток. Действия разных процессов в одной программе необходимо согласовать, для этого в средах параллельного программирования предусмотрены разные механизмы: в MPI – передача сообщений, в OpenMP – общие переменные и автоматическое распараллеливание циклов и т. д. Технологии типа MPI – это не только указание особых функций и инструкций в коде, но и среда запуска программы. Особенно это относится к средам, использующим несколько вычислительных узлов, – ведь на каждом узле надо запустить экземпляр (а то и не один) программы и «подружить» его с остальными запущенными экземплярами той же программы (но не соседней). Вот тут и начинаются заботы системного администратора. Все установленные параллельные среды надо оптимально настроить, а при возникновении проблем – уметь расшифровать их диагностику.
Например, в кластере используется скоростная коммуникационная сеть (InfiniBand или другая) и обычный Ethernet для управления. Установленная среда MPI работает, но эффективность работы программ низкая. Нередко причиной является неверная настройка, в результате которой MPI использует медленную управляющую сеть вместо скоростной.
Виды кластеров
Когда говорят «кластер», подразумевают множество компьютеров, объединённых в нечто единое. Но вариантов этого «нечто» может быть несколько. Они отличаются целью и, как следствие, – реализацией.
Первый вид кластеров – High-Availability, или кластеры высокой доступности. Их задача – предоставить доступ к какому-то ресурсу с максимальной скоростью и минимальной задержкой. Ресурсом обычно выступают web-сайт, база данных или другой сервис. В таком кластере при выходе из строя одного узла работоспособность всего ресурса сохраняется – клиенты сбойного узла переподключаются и получают доступ к ресурсу с другого узла кластера. Очень похожий принцип применяется в «облачных» технологиях: вы не знаете, на каком именно узле будет работать ваше приложение или образ операционной системы, облако само подберёт свободные ресурсы.
Другой вид кластеров – High Productivity. Этот тип похож на предыдущий, но в данном случае все узлы кластера уже работают над одним заданием, разбитым на части. Если какой-то узел отказал, его часть задания отправляется другому; если в кластер добавляются новые узлы, им выделяются не посчитанные ещё части, и общий счёт идёт быстрее. В качестве примеров можно назвать GRID, программы типа Seti@home, Folding@Home. Однако с помощью таких кластеров может быть решён только узкий класс задач. Да и сам кластер для таких задач нередко становится не нужен, можно воспользоваться домашними компьютерами или серверами, связав их через локальную сеть или Интернет.
Третий вид – High Performance (HPC – High Performance Computing). Именно он интересен нам. В отличие от остальных, выход из строя одного из узлов кластера, как правило, ведёт к аварийному завершению параллельной программы, только в редких случаях выполнение программы автоматически продолжается с сохранённой ранее контрольной точки. Именно поэтому, в отличие от предыдущих видов, HPC-кластеры менее устойчивы в работе, и без должного контроля и мониторинга использовать их просто не получится.
Важное отличие этого вида кластеров от остальных – тесная связность всех узлов. Это и самые быстрые сети, соединяющие узлы, и высокопроизводительные параллельные файловые системы, и средства дополнительной синхронизации узлов, и другие средства, важные для параллельных программ. Приложения, работающие на таких кластерах, как правило, работают в модели передачи сообщений между параллельно запущенными процессами. Если запустить их на множестве компьютеров, соединённых медленной сетью, то они бóльшую часть времени потратят на ожидание информации друг от друга.
Идеал, к которой стремятся все производители кластеров, – создать виртуальный компьютер с большой памятью и огромным числом вычислительных ядер. К сожалению, реальность ещё очень далека от идеала, и сейчас любой вычислительный кластер – это всё-таки множество отдельных вычислительных узлов, соединённых быстрой сетью. От сети в таком кластере требуется не только скорость (пропускная способность), но и низкая величина задержек или накладных расходов (латентность). Большинство параллельных программ обмениваются сообщениями часто, а значит, время на инициализацию отправки и приёма сообщения начинает играть большую роль. На сети с большой латентностью некоторые программы могут работать в разы медленнее, чем на сети, где латентность низкая.
Кластеры и суперкомпьютеры – общее и разное
Мы только что поговорили о кластерах. Но всегда ли слово «суперкомпьютер» означает кластер? Нет, не всегда. Важная черта кластера – возможность сборки из серийных общедоступных компонентов. Т. е. можно купить все компоненты кластера в магазине и, обладая достаточным опытом, собрать его самостоятельно.
Суперкомпьютер в общем случае – изделие с уникальными компонентами, производимое одним поставщиком. В качестве примера приведём серию Blue Gene компании IBM – архитектура этих машин похожа на кластер, на них доступны те же программные средства, что и на вычислительных кластерах, но купить Blue Gene можно только у IBM или их дистрибьюторов.
Построить Blue Gene самостоятельно невозможно: ключевые компоненты отдельно не продаются. И дело не в марке, а в уникальных технологиях. Кроме Blue Gene есть множество иных серий, иных уникальных разработок. Обратный пример – «вычислительные фермы», т. е. группы компьютеров, работающих над одной задачей, но обычно даже не передающие данные друг другу, или кластеры класса «BeoWulf[2]», т. е. собранные практически из подручных средств.
Как видим, грань между понятиями «кластер» и «не-кластер» достаточно чёткая, но какой кластер считать суперкомпьютером, а какой нет – вопрос размытый. Часто вместо «кластер» говорят более тактично: «обладающий кластерной архитектурой». В этой книге мы будем рассматривать технологии, доступные для всех или большинства. Следовательно, большинство из них будет относится именно к кластерам. Но это не значит, что в вычислительных комплексах, которые мы формально не относим к кластерам, этих технологий не встретится. Большинство современных суперкомпьютеров используют те же наработки, что и кластеры, более того, почти все они построены как кластеры с добавлением особо быстрых сетей, техник работы с общей памятью, синхронизации или иных технологий. А значит, все знания о кластерах вам только помогут.